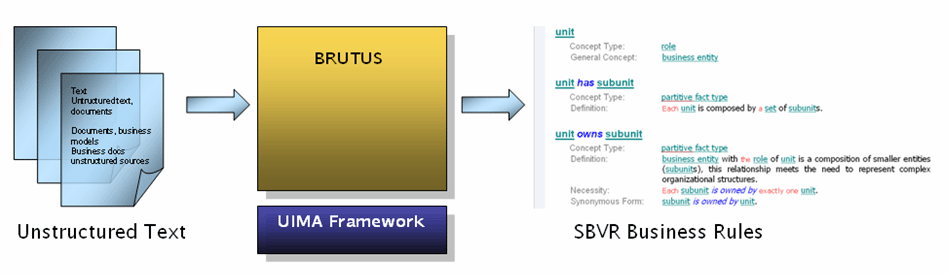
BRUTUS overview
BRUTUS intends to be a reusable
component (annotator based on UIMA
framework) which automatically extracts business rules (compliant
with the SBVR
metamodel and Structured English notation) from unstructured documents
and business knowledge sources.
A common approach to parsing free text is to separate different levels of linguistic processing into modules that are then pipelined together.
From a functional viewpoint BRUTUS architecture is composed of five primitive Analysis Engines (AEs):
Language Identifier
Sentence Detector and Tokenizer
Part of Speech Tagger
Business Rule Detector
SBVR Formatter
BRUTUS uses statistical machine learning techniques
based on the maximum entropy probability to POS
tag, chunk and parse English phrases models.
In particular, the
chunker and the parser uses Penn Treebank constituents as the basis
for the treebank construction and are based on the pre-trained models
provided by the OpenNLP
project. Such models are trained for the various components and
are appropriate when the user has no a priori knowledge about the
domain of the annotating data. Nevertheless, in case of specific
domains BRUTUS allows a user to
use its own models (with ad hoc training).
The list of Penn Treebank
tags used in BRUTUS can be found here.
|
